NLP-Based Grant Analysis
Exploratory Analysis of NSF Standard Grants Using NLP and Data Visualization Tools
We start by retrieving the NSF Grant data files. The grant data, including abstracts of the funded projects, are available as zipped XML files on the NSF web pages. We download the data and extract the relevant parts with BeautifulSoup. Since the zip files are rather large and need a lot of memory, we work with one zip file at a time and append the results to an uncompressed CSV file.
from bs4 import BeautifulSoup
from zipfile import ZipFile
import pandas as pd
from glob import glob
def parse_xml(soup):
xdata = []
xdata.append(soup.find('AwardEffectiveDate').string[-4:])
xdata.append(soup.find('AwardInstrument').find('Value').string)
xdata.append(soup.find('Directorate').find('LongName').string)
xdata.append(soup.find('Division').find('LongName').string)
xdata.append(int(soup.find('AwardAmount').string))
xdata.append(soup.find('AbstractNarration').string)
return xdata
def readzips(zfiles, outfile):
headers = ['year', 'instrument', 'directorate', 'division', 'funding', 'abstract']
df = pd.DataFrame(columns=headers)
df.to_csv('./nsf-standard-grants.csv', encoding='utf-8')
for zf in zfiles:
xlist = []
with ZipFile(zf) as z:
for filename in z.namelist():
if filename[-3:] == 'xml':
with z.open(filename) as f:
soup = BeautifulSoup(f, 'xml')
xlist.append(parse_xml(soup))
df = pd.DataFrame(xlist, columns=headers)
df = df[df.instrument == 'Standard Grant']
df.to_csv(outfile, encoding='utf-8', header=None, mode='a')
del df, xlist
outfile = './nsf-standard-grants.csv'
readzips(glob('*.zip'), outfile)
We then read the entire data set into memory from the CSV file, remove duplicated rows and compress the data.
df = pd.read_csv(outfile, index_col=0, encoding='utf-8')
df.drop_duplicates(inplace=True)
df.to_csv(outfile + '.xz', encoding='utf-8')
Next we load some useful libraries for exploratory data analysis and visualisation.
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer, TfidfTransformer
from sklearn import preprocessing
from sklearn.manifold import TSNE, SpectralEmbedding
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.decomposition import LatentDirichletAllocation, NMF, TruncatedSVD
from sklearn.metrics import confusion_matrix
from sklearn.pipeline import Pipeline
from umap import UMAP
import matplotlib.pyplot as plt
import seaborn as sns
We load the previously saved grant data to a Pandas dataframe and check the structure and headings of the data.
df = pd.read_csv('./nsf-standard-grants.csv.xz', index_col=0, encoding='utf-8')
df.head()
| year | instrument | directorate | division | abstract | funding | |
|---|---|---|---|---|---|---|
| 0 | 2008 | Standard Grant | Directorate For Engineering | Div Of Civil, Mechanical, & Manufact Inn | NSF Proposal # 0800628: Management in Supply C... | 281167.0 |
| 1 | 2008 | Standard Grant | Direct For Computer & Info Scie & Enginr | Division Of Computer and Network Systems | Proposal Summary: The Association for Computin... | 20200.0 |
| 2 | 2008 | Standard Grant | Directorate For Engineering | Div Of Civil, Mechanical, & Manufact Inn | The research objective of this Grant Opportuni... | 177948.0 |
| 3 | 2008 | Standard Grant | Directorate For Engineering | Div Of Civil, Mechanical, & Manufact Inn | Abstract <br/>The research objective of this a... | 222600.0 |
| 4 | 2008 | Standard Grant | Directorate For Engineering | Div Of Civil, Mechanical, & Manufact Inn | This research will lead to advanced, functiona... | 309973.0 |
Let’s see how many abstracts there are per each directorate.
df.groupby('directorate').count()['abstract']
directorate
Dir for Tech, Innovation, & Partnerships 3495
Direct For Biological Sciences 10594
Direct For Computer & Info Scie & Enginr 18405
Direct For Education and Human Resources 6909
Direct For Mathematical & Physical Scien 20218
Direct For Social, Behav & Economic Scie 12068
Directorate For Engineering 26773
Directorate For Geosciences 13157
Directorate for Computer & Information Science & Engineering 2
Directorate for STEM Education 3115
Directorate for Social, Behavioral & Economic Sciences 3
Office Of Polar Programs 3
Office Of The Director 1708
Name: abstract, dtype: int64
Some of the directorates seem to have been spelled in multiple ways. We clean up the data by remapping the directorates to a more compact list.
dir_map = {
'Dir for Tech, Innovation, & Partnerships': 'Tech, Innovation, & Partnerships',
'Direct For Biological Sciences': 'Biological Sciences',
'Direct For Computer & Info Scie & Enginr': 'Computer & Information Science & Engineering',
'Direct For Education and Human Resources': 'Education',
'Direct For Mathematical & Physical Scien': 'Mathematical & Physical Sciences',
'Direct For Social, Behav & Economic Scie': 'Social, Behavioral & Economic Sciences',
'Directorate For Engineering': 'Engineering',
'Directorate For Geosciences': 'Geosciences',
'Directorate for Computer & Information Science & Engineering': 'Computer & Information Science & Engineering',
'Directorate for STEM Education': 'Education',
'Directorate for Social, Behavioral & Economic Sciences': 'Social, Behavioral & Economic Sciences',
'Office Of Polar Programs': 'Geosciences',
'Office Of The Director': 'Office Of The Director'
}
df['directorate'] = df['directorate'].map(dir_map)
We drop rows that contain an empty abstract from our dataframe and recheck how many abstracts there are per each directorate.
df.dropna(subset=['abstract'], inplace=True)
df.groupby('directorate').count()['abstract']
directorate
Biological Sciences 10594
Computer & Information Science & Engineering 18407
Education 10024
Engineering 26773
Geosciences 13160
Mathematical & Physical Sciences 20218
Office Of The Director 1708
Social, Behavioral & Economic Sciences 12071
Tech, Innovation, & Partnerships 3495
Name: abstract, dtype: int64
In total, we have over 100k abstracts in our data set.
df.shape
(116450, 6)
We can cross-tabulate the number of grants per directorate and year.
directorates = sorted(df['directorate'].unique())
pd.crosstab(df.directorate, df.year)
| year | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| directorate | ||||||||||||||||||
| Biological Sciences | 0 | 17 | 495 | 1267 | 829 | 670 | 663 | 648 | 666 | 734 | 748 | 694 | 540 | 623 | 790 | 584 | 569 | 57 |
| Computer & Information Science & Engineering | 0 | 12 | 894 | 1480 | 1164 | 1098 | 1216 | 1133 | 1165 | 1328 | 1347 | 1363 | 1430 | 1366 | 1324 | 1010 | 1022 | 55 |
| Education | 0 | 4 | 470 | 755 | 689 | 611 | 632 | 605 | 579 | 708 | 735 | 664 | 714 | 666 | 735 | 719 | 667 | 71 |
| Engineering | 0 | 41 | 1118 | 2381 | 2162 | 1855 | 1900 | 1981 | 2080 | 2175 | 2419 | 2068 | 1760 | 1338 | 1232 | 1043 | 1115 | 105 |
| Geosciences | 1 | 19 | 543 | 1566 | 1155 | 1008 | 933 | 759 | 732 | 770 | 824 | 739 | 673 | 838 | 883 | 892 | 755 | 70 |
| Mathematical & Physical Sciences | 0 | 38 | 826 | 1997 | 1411 | 1176 | 1282 | 1104 | 1216 | 1293 | 1323 | 1234 | 1516 | 1541 | 1514 | 1282 | 1440 | 25 |
| Office Of The Director | 0 | 5 | 106 | 194 | 226 | 165 | 91 | 74 | 116 | 69 | 53 | 70 | 97 | 92 | 81 | 127 | 110 | 32 |
| Social, Behavioral & Economic Sciences | 0 | 12 | 581 | 1194 | 975 | 801 | 872 | 807 | 843 | 851 | 802 | 804 | 696 | 697 | 873 | 660 | 577 | 26 |
| Tech, Innovation, & Partnerships | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 432 | 831 | 805 | 763 | 658 | 5 |
Classification
Let’s train a simple linear classifier and check how well the model can predict under which directorate each abstract belongs. First we transform the abstracts to a document-term matrix using CountVectorizer. We use unigrams as features since the vocabulary size becomes rather large with bigrams.
vect_clf = CountVectorizer(stop_words='english', ngram_range=(1,1), max_df=0.2, min_df=2)
X = vect_clf.fit_transform(df.abstract)
X.shape
(116450, 85757)
We set up a classifier pipeline with TfidfTransformer and LinearSVC. Note that we did not use TfidfVectorizer above in order to avoid data leakage during cross-validation but instead apply TfidfTransformer separately for each train and test set.
clf = LinearSVC(class_weight='balanced')
tfidf = TfidfTransformer(sublinear_tf=True)
pipe = Pipeline([('tfidf', tfidf), ('clf', clf)])
Now we can check how well the model performs. We do this by a 5-fold cross-validation and check the average accuracy score.
score = cross_val_score(pipe, X, df.directorate, cv=5, n_jobs=-1)
print(score, score.mean())
[0.8455131 0.87084586 0.86994418 0.84753113 0.82271361] 0.8513095749248605
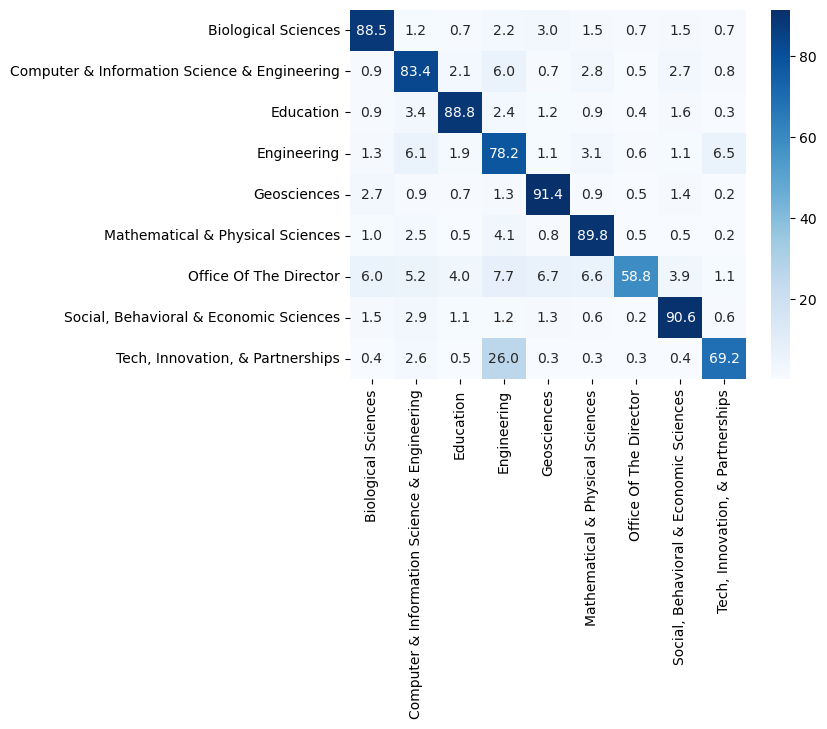
Accuracy score of 0.85 is quite decent. We will also check which directorates the model mixes up by calculating the confusion matrix between the predicted and actual directorates.
pred_directorate = cross_val_predict(pipe, X, df.directorate, cv=5, n_jobs=-1)
cfm = (100*confusion_matrix(df.directorate, pred_directorate, labels=directorates, normalize='true')).round(1)
The model has learned to separate Geosciences and Social, Behavioral & Economic Sciences most consistently from the other directorates. “Office of the Director” and “Tech, Innovation, & Partnerships” are most often mixed with other directorates but these two have the lowest number of grants which likely has a negative impact on the accuracy.
sns.heatmap(cfm, cmap='Blues', annot=True, fmt='.1f', xticklabels=directorates, yticklabels=directorates)
plt.plot();
Visualisation
Let’s try to visualize the dataset. This time we transform the full dataset with TfidfVectorizer to a normalized document-term matrix.
vect = TfidfVectorizer(stop_words='english', ngram_range=(1,1), sublinear_tf=True, max_df=0.2, min_df=10)
X = vect.fit_transform(df.abstract)
fnames = vect.get_feature_names_out()
X.shape
(116450, 33219)
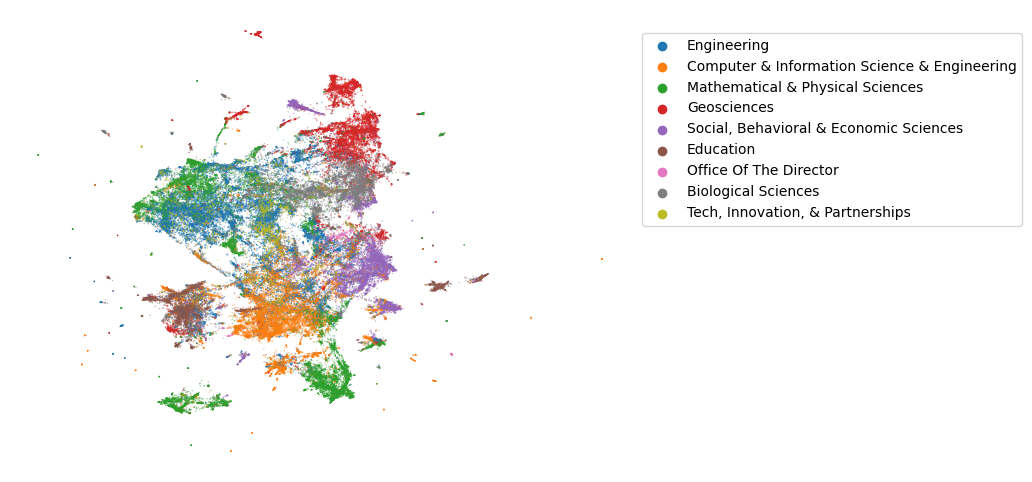
We embed the vectorized abstracts to 2 dimensions with UMAP using the angle between the vectors (“cosine distance”) as the distance metric.
Xr = UMAP(n_components=2, n_neighbors=10, metric='cosine').fit_transform(X)
df['x'] = Xr[:,0]
df['y'] = Xr[:,1]
Now we can create a scatterplot of the data. The resulting plot shows that abstracts coming from the same directorate are most often fairly well clumped together, but there are also some clusters that contain abstracts from multiple directorates. This seems to happen especially with abstracts from Mathematical & Physical Sciences and Engineering.
fig, ax = plt.subplots(figsize=[8,6])
sns.scatterplot(data=df, x='x', y='y', hue='directorate', s=1, alpha=0.5, linewidth=0, ax=ax)
plt.axis('off')
plt.legend(bbox_to_anchor=(1.02, 0.95), loc='upper left', borderaxespad=0)
plt.show()
Next we try to identify some keywords that have been emerging in the last few years. Before that, we will do some simple preprocessing of the abstract texts with spaCy.